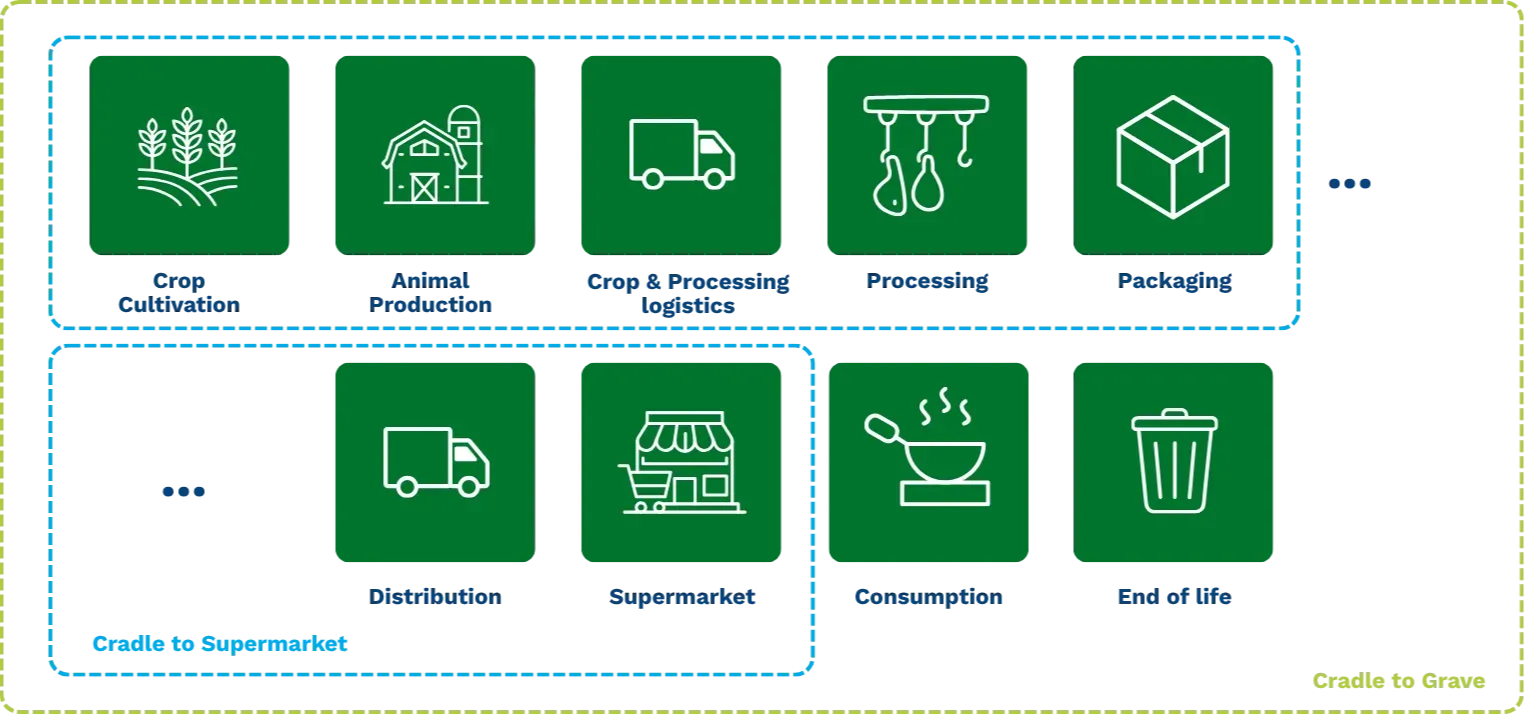
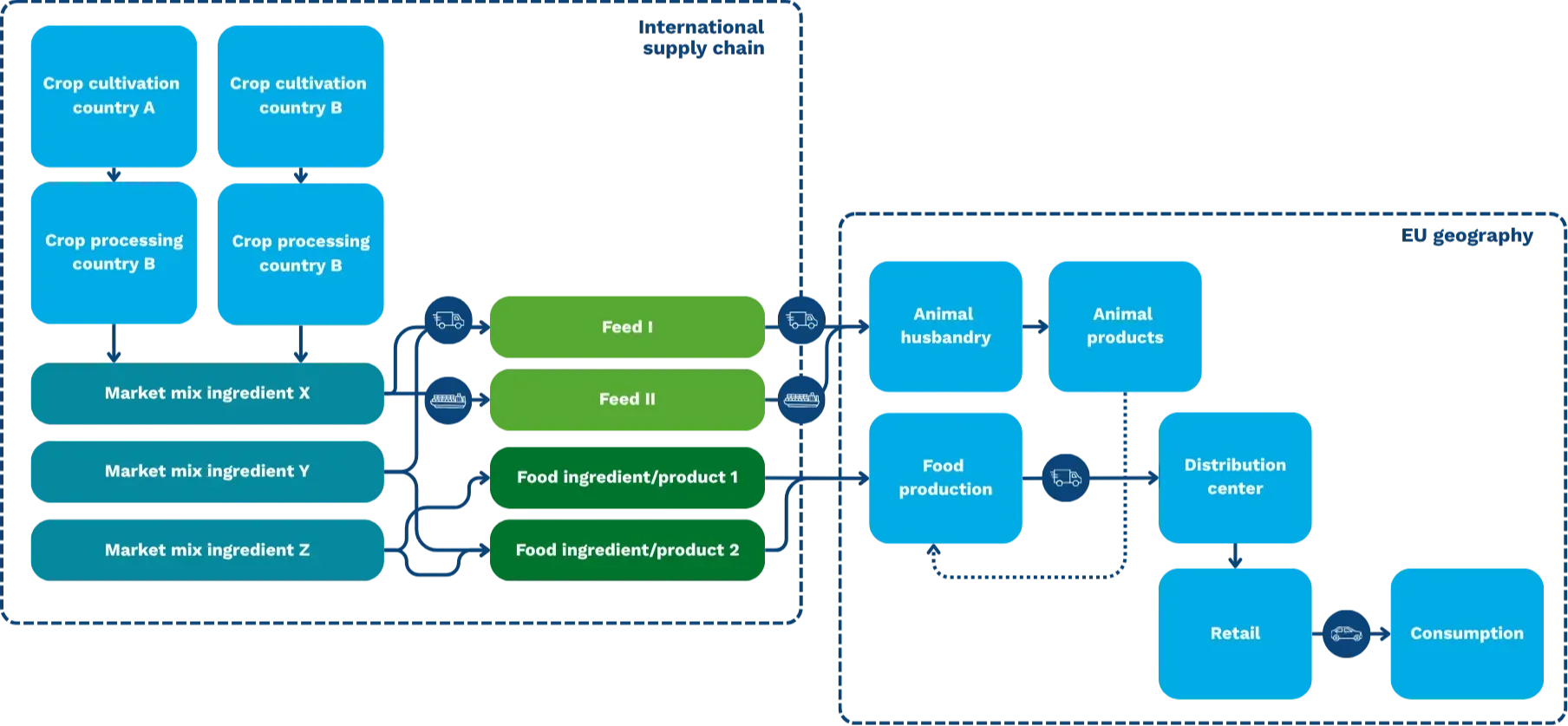
As the global food system faces increasing pressure to reduce its environmental impact, the need for robust, harmonized, and high-quality data has never been more critical. To support this transition, the European Food Safety Authority (EFSA) commissioned the development of the European Environmental Footprint of Food (EFF) database. Developed by Mérieux NutriSciences | Blonk in collaboration with RIVM (the Dutch National Institute for Public Health and the Environment), the EFF database is a comprehensive resource designed to provide the consistent footprint data needed to evaluate and understand the environmental performance of food products across Europe.
In this article, we explore the development of the EFF database, and how our Data Generation Pipeline (DGP) enabled the creation of this large-scale, high-quality LCA database.